Reza J. Torbati, Shubham Lohiya, Shivika Singh, Meher Shashwat Nigam, Harish Ravichandar
📄 Paper 💻 Code 📁 Supplementary Material
About
Recent years have seen rapid improvements in Multi-Robot Reinforcement Learning (MRRL). However, many of these novel algorithms have limited real world testing. Although there are several environments for evaluating MRRL algorithms, few of them offer dynamics similar to what real robots experience, and fewer can also test Sim2Real performance. To address these issues, we introduce MARBLER: Multi-Agent RL Benchmark and Learning Environment for the Robotarium. MARBLER is a platform built using the Robotarium’s simulator that allows for rapid prototyping of new MRRL experiments.
MARBLER – Platform Structure
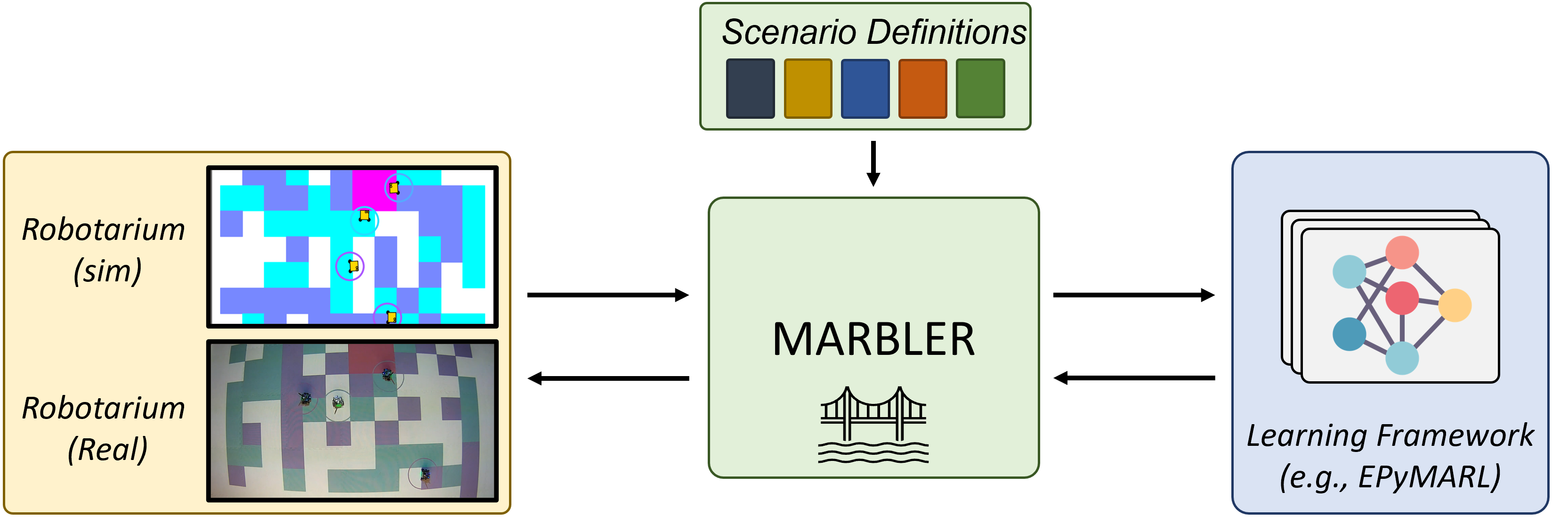
MARBLER comprises several components that form the foundation of the platform:
Core: The Core component serves as the fundamental building block of MARBLER, leveraging the Robotarium’s python simulator. It encompasses critical functionalities necessary for the environment, such as environment resetting and discrete time step advancement.
Scenarios: The scenarios module defines the environments the robots interact in and the specific tasks they must accomplish. MARBLER offers a collection of pre-defined scenarios, enabling researchers to readily explore various environments. MARBLER also makes it easy for researchers to define their own environments for the Robotarium.
Gym Interface: Each scenario within MARBLER is registered as a Gym environment, allowing direct compatibility with the algorithms and tools that support the OpenAI Gym interface.
Test Pipeline: The Test Pipeline provides a streamlined process for importing trained robots into the simulation environment, allowing visualization of robots performance and collection of test data.
Results
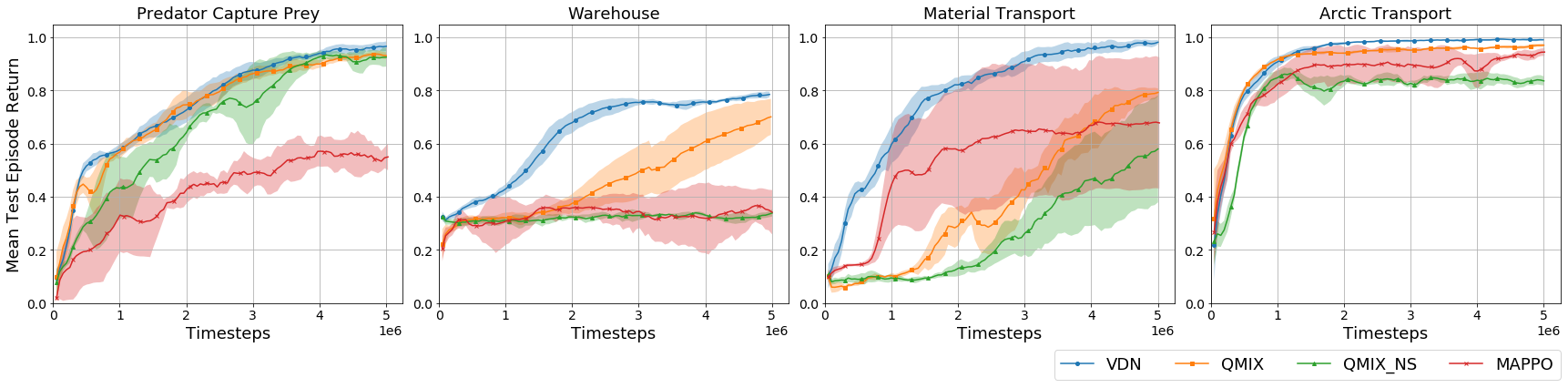
We evaluated MAPPO, QMIX, VDN, and QMIX_NS in 4 scenarios using MARBLER. Overall, VDN achieved the best performance across scenarios with QMIX also performing well. The performance of QMIX vs QMIX_NS depended on the heterogeneity of the environment. There were few differences between simulation and real-world performance, highlighting MARBLER’s realistic dynamics.
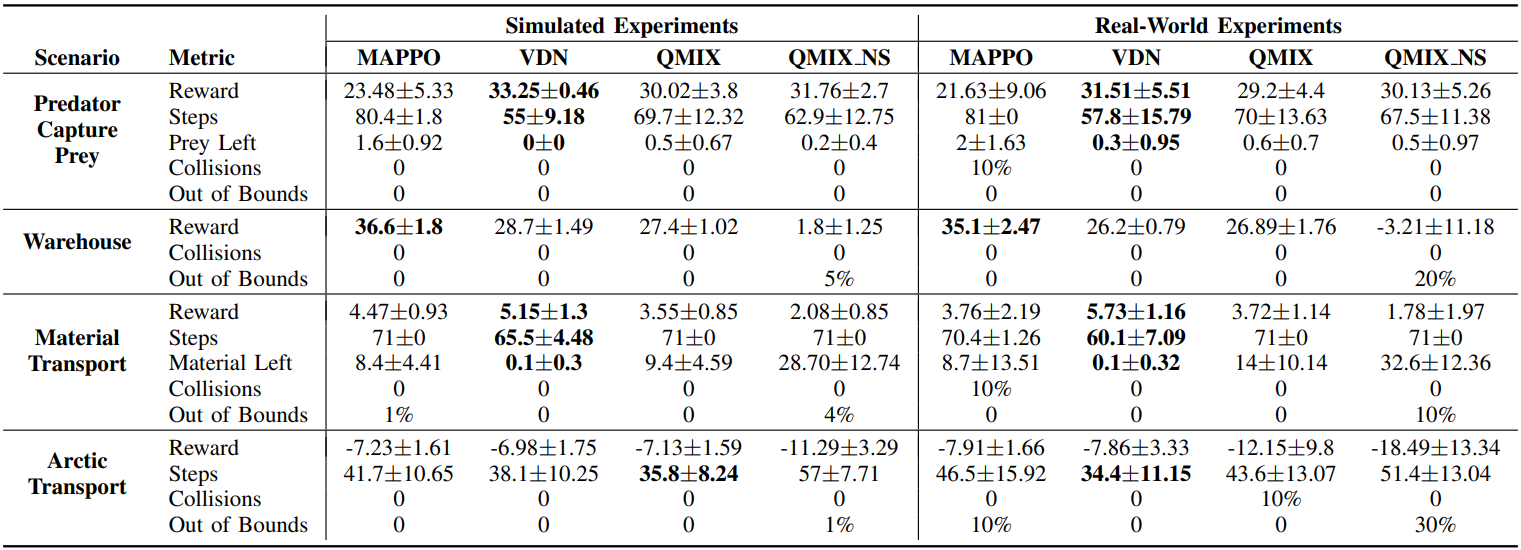
The videos of the test runs on the Robotarium test-bed can be viewed here.
Demo
Citation
@misc{torbati2023marbler,
title={MARBLER: An Open Platform for Standardized Evaluation of Multi-Robot Reinforcement Learning Algorithms},
author={Reza Torbati and Shubham Lohiya and Shivika Singh and Meher Shashwat Nigam and Harish Ravichandar},
year={2023},
eprint={2307.03891},
archivePrefix={arXiv},
primaryClass={cs.RO}
}
Acknowledgements
We thank the researchers and staff at the Robotarium for providing access to their simulator and real-world testbed.